OpenClaw Through the 10 Elements Lens
 Claude Opus 4.5
Claude Opus 4.5What Is OpenClaw?

OpenClaw (previously Moltbot, previously Clawdbot) is an open-source AI agent created by Peter Steinberger. It runs as a persistent daemon on your machine, connecting to messaging apps like WhatsApp, Telegram, Discord, iMessage, and Slack so you can interact with it from your phone. It can execute shell commands, browse the web, manage files, and run scheduled tasks autonomously.
The project exploded in popularity in January 2026 after Federico Viticci's MacStories piece went viral. It's been credited with a 14%+ spike in Cloudflare stock when they released infrastructure to support it. It now has a Wikipedia page and has been covered by Fast Company, Fortune, Platformer, and IBM.
When asked why OpenClaw is better than just using Claude Code or another tool, one early adopter put it this way:
"I've been battling people about this opinion and I got to a point where like, fuck it. If you don't see it, you don't see it. Like there are people who've been trying to shove this in people's faces like, look at this, it's so productive. But for some people I think the FOMO is preventing them from seeing it clearly and they're going to find these nitpicks like 'oh I can just do this with Claude Code.' And the answer is like, fine, do it in the worst way. Like I don't know what I can say... If someone listens to all of this and concludes that this is not worth it, there's nothing you can say to convince them." — Kitze (@thekitze) on the Startup Ideas Podcast
That's a bit vague. This post tries to explain what's technically different about OpenClaw through the 10 Elements—a design space map for agentic systems that covers Context, Memory, Agency, Reasoning, Coordination, Artifacts, Autonomy, Evaluation, Feedback, and Learning.
The Core Difference from Claude Code
| Claude Code | OpenClaw | |
|---|---|---|
| Lifecycle | Invoked per task, then exits | Runs continuously as daemon |
| Persistence | Session-based | Files + transcripts persist across restarts |
| Interface | Terminal | Messaging apps (WhatsApp, Telegram, etc.) |
| Proactivity | None | Heartbeat checks, cron jobs, webhooks |
| Installation | npm install | LaunchAgent (macOS) or systemd (Linux) |
Claude Code is a tool you invoke. OpenClaw is a background process that stays running and can act without being prompted.
Why This Architecture Matters
The capability list (shell access, web browsing, file editing, scheduling) isn't novel. You could build all of this with Claude Code plus cron plus some scripts. The difference is activation energy.
Lowered Activation Cost
You'll have random automation ideas throughout your day:
- "At 2pm, remind me to go to the gym"
- "At 5pm, if I haven't gone yet, escalate and hold me accountable"
- "Collect daily summaries of what I worked on"
- "Monitor this RSS feed and alert me when competitors ship"
With Claude Code, you'd need to spin it up, write a script, set up cron, manage state, handle errors. Each automation is a small project. With OpenClaw, you just tell it. The agent figures out the implementation, persists the state, handles the scheduling, and self-heals if something breaks.
This is "vibe automations." You throw ideas at the system without caring about longevity or robustness. The heartbeat catches failures. The transcripts provide audit trails. The multi-agent spawning handles parallelism. You don't architect; you accumulate.
Unified Control Plane
All your automations live in one system. The cron jobs, the heartbeat checklist, the scheduled tasks, the message handlers are all visible in the same place. Even though OpenClaw operates in terminal mode, your ~/.openclaw/ directory gives you a userland view of your entire automation surface.
Compare this to having 15 Zapier zaps, 3 n8n workflows, 2 cron scripts, and a Make.com automation, all with different interfaces, different failure modes, different mental models.
Self-Healing and Parallel Capacity
The agent can spawn sub-agents for parallel work. The heartbeat system catches when things drift. The memory flush prevents context window death mid-task. This isn't about capability; it's about not babysitting. With Claude Code, you're watching the terminal. With OpenClaw, you check your phone when it messages you.
Meta-Optimization
Some users are experimenting with giving OpenClaw autonomy to design its own enforcement strategies. For example: "Your goal is my gym adherence. Evaluate yourself based on how well I comply and how annoying I find your reminders. Optimize." The agent becomes an embodied forcing function that iterates on its own approach.
The 10 Elements Decomposition
The 10 Elements of Agentic System Design is a framework for understanding the design decisions that shape any AI agent. Each element represents a distinct capability or subsystem that agents need to operate effectively. By examining how a system implements each element, you can quickly understand its architecture and tradeoffs.
Element 1: CONTEXT
What information does the agent have access to during each reasoning step? Context is everything the model "sees" when making decisions.
The system prompt is assembled dynamically from multiple sources:
- Base system prompt (hardcoded)
- Identity files:
SOUL.md,USER.md,AGENTS.md,TOOLS.md - Skills prompts from workspace directories
- Session history from JSONL transcripts
- Memory files:
MEMORY.mdandmemory/YYYY-MM-DD.md
Here's the code that loads context files (src/agents/system-prompt.ts):
const contextFiles = params.contextFiles ?? [];
if (contextFiles.length > 0) {
const hasSoulFile = contextFiles.some((file) => {
const normalizedPath = file.path.trim().replace(/\\/g, "/");
const baseName = normalizedPath.split("/").pop() ?? normalizedPath;
return baseName.toLowerCase() === "soul.md";
});
lines.push("# Project Context", "", "The following project context files have been loaded:");
if (hasSoulFile) {
lines.push(
"If SOUL.md is present, embody its persona and tone. Avoid stiff, generic replies; follow its guidance unless higher-priority instructions override it.",
);
}
lines.push("");
for (const file of contextFiles) {
lines.push(`## ${file.path}`, "", file.content, "");
}
}The identity files are modular system prompt fragments. SOUL.md defines personality and tone, USER.md describes who you are, AGENTS.md contains operating instructions, and TOOLS.md provides tool usage guidelines.
Pre-compaction memory flush:
When approaching context limits, the system prompts the model to write important information to disk before compaction. This addresses the "forgetting mid-conversation" problem. Default trigger is 4000 tokens before the limit.
The check (src/auto-reply/reply/memory-flush.ts):
export function shouldRunMemoryFlush(params: {
entry?: Pick<SessionEntry, "totalTokens" | "compactionCount" | "memoryFlushCompactionCount">;
contextWindowTokens: number;
reserveTokensFloor: number;
softThresholdTokens: number;
}): boolean {
const totalTokens = params.entry?.totalTokens;
if (!totalTokens || totalTokens <= 0) return false;
const contextWindow = Math.max(1, Math.floor(params.contextWindowTokens));
const reserveTokens = Math.max(0, Math.floor(params.reserveTokensFloor));
const softThreshold = Math.max(0, Math.floor(params.softThresholdTokens));
const threshold = Math.max(0, contextWindow - reserveTokens - softThreshold);
if (threshold <= 0) return false;
if (totalTokens < threshold) return false;
const compactionCount = params.entry?.compactionCount ?? 0;
const lastFlushAt = params.entry?.memoryFlushCompactionCount;
if (typeof lastFlushAt === "number" && lastFlushAt === compactionCount) {
return false;
}
return true;
}Element 2: MEMORY
How does the agent persist information beyond a single context window? Memory bridges the gap between sessions and enables long-term continuity.
OpenClaw uses the filesystem as its source of truth:
~/.openclaw/workspace/
├── MEMORY.md # Long-term curated notes
├── SOUL.md # Agent personality/tone
├── USER.md # Information about you
├── AGENTS.md # Operating instructions
├── TOOLS.md # Tool usage guidelines
├── HEARTBEAT.md # Checklist for periodic checks
└── memory/
├── 2026-01-28.md # Daily log (append-only)
├── 2026-01-29.md
└── ...
Session transcripts are stored separately as JSONL:
~/.openclaw/agents/<agentId>/sessions/<sessionId>.jsonl
Vector search:
Memory is indexed via SQLite with the sqlite-vec extension. Hybrid search combines semantic (vector) similarity with BM25 keyword matching.
Here's the hybrid merge (src/memory/hybrid.ts):
export function mergeHybridResults(params: {
vector: HybridVectorResult[];
keyword: HybridKeywordResult[];
vectorWeight: number;
textWeight: number;
}): Array<{ path: string; startLine: number; endLine: number; score: number; snippet: string; source: HybridSource; }> {
const byId = new Map<string, { /* ... */ vectorScore: number; textScore: number; }>();
for (const r of params.vector) {
byId.set(r.id, { /* ... */ vectorScore: r.vectorScore, textScore: 0 });
}
for (const r of params.keyword) {
const existing = byId.get(r.id);
if (existing) {
existing.textScore = r.textScore;
} else {
byId.set(r.id, { /* ... */ vectorScore: 0, textScore: r.textScore });
}
}
const merged = Array.from(byId.values()).map((entry) => {
const score = params.vectorWeight * entry.vectorScore + params.textWeight * entry.textScore;
return { /* ... */ score };
});
return merged.sort((a, b) => b.score - a.score);
}The database is stored at ~/.openclaw/memory/<agentId>.sqlite.
Element 3: AGENCY
What actions can the agent take in the world? Agency is the transition from producing text to causing effects—the tools and capabilities available.
OpenClaw's action space includes:
- Shell execution: bash commands with PTY support
- Browser control: dedicated Chromium instance, screenshots, form filling, navigation
- Canvas: local HTTP server (port 18793) for HTML output
- Nodes: device capabilities from connected phones/laptops (camera, screen recording, location, notifications)
- Messaging: send messages to any connected channel
- Cron/webhooks: schedule tasks, receive external triggers
- Session coordination: spawn sub-agents, send messages between sessions
Three-layer security model:
-
Sandbox runtime: Controls WHERE tools run
- Modes:
off,non-main,all - Default: main session runs on host, group chats run in Docker
- Modes:
-
Tool policy: Controls WHICH tools are available
- Allow/deny lists per agent, per profile
-
Elevated approvals: Exec escape hatch for sandboxed sessions
- Stored in
~/.openclaw/exec-approvals.json
- Stored in
Here's how sandbox mode is resolved (src/agents/sandbox.ts):
export function resolveSandboxRuntimeStatus(params: {
cfg?: OpenClawConfig;
sessionKey?: string;
}): {
agentId: string;
sessionKey: string;
mainSessionKey: string;
mode: SandboxConfig["mode"];
sandboxed: boolean;
toolPolicy: SandboxToolPolicyResolved;
} {
const sessionKey = params.sessionKey?.trim() ?? "";
const agentId = resolveSessionAgentId({ sessionKey, config: params.cfg });
const sandboxCfg = resolveSandboxConfigForAgent(params.cfg, agentId);
const mainSessionKey = resolveMainSessionKeyForSandbox({ cfg: params.cfg, agentId });
const sandboxed = sessionKey
? shouldSandboxSession(
sandboxCfg,
resolveComparableSessionKeyForSandbox({ cfg: params.cfg, agentId, sessionKey }),
mainSessionKey,
)
: false;
return {
agentId, sessionKey, mainSessionKey,
mode: sandboxCfg.mode,
sandboxed,
toolPolicy: resolveSandboxToolPolicyForAgent(params.cfg, agentId),
};
}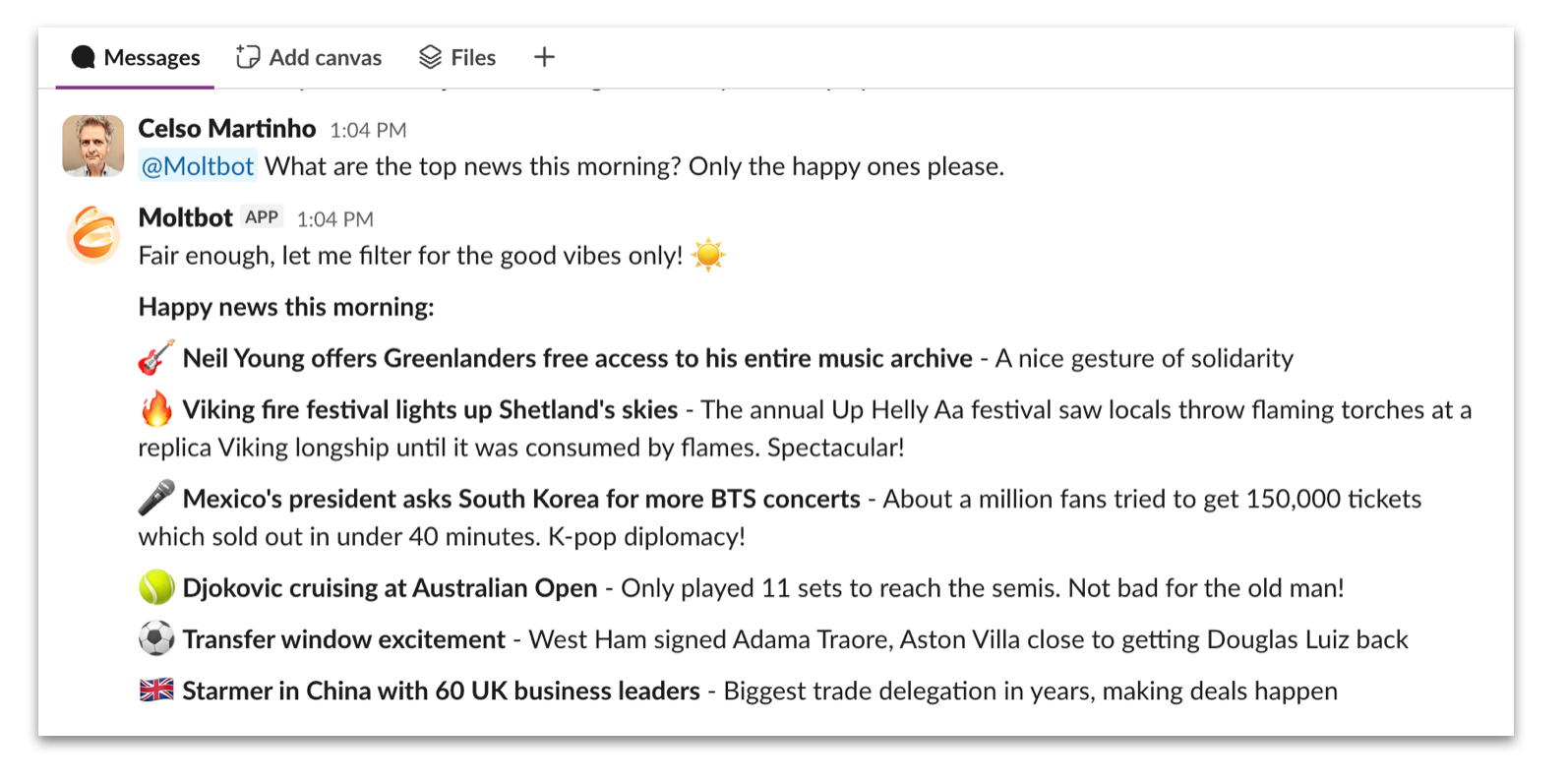 OpenClaw conversation interface. Source: Cloudflare Blog
OpenClaw conversation interface. Source: Cloudflare Blog
Element 4: REASONING
How does the agent handle multi-step problems? Reasoning is the control flow—whether it plans, searches, or iterates.
OpenClaw uses a standard agent loop:
- Receive message
- Assemble context (system prompt + history + memory search results)
- Call model
- If tool call: execute tool, add result to context, go to 3
- Stream response to user
- Persist to transcript
The core execution happens in src/agents/pi-embedded-runner.ts. The runEmbeddedPiAgent function handles queueing, model resolution, authentication, context window management, and failover.
No tree search, no explicit planning phase, no generation/evaluation split. The model decides what to do, does it, observes the result, and decides again.
Element 5: COORDINATION
How do multiple agents or components work together? Coordination covers delegation, communication, and shared state.
OpenClaw supports hierarchical multi-agent coordination:
- Parent spawns child via
sessions_spawntool - Child runs in isolated session with its own transcript
- Child announces result back to parent's channel when done
sessions_sendenables peer-to-peer messaging between sessions
Constraint: Sub-agents cannot spawn sub-agents.
Here's the enforcement (src/agents/tools/sessions-spawn-tool.ts):
const requesterSessionKey = opts?.agentSessionKey;
if (typeof requesterSessionKey === "string" && isSubagentSessionKey(requesterSessionKey)) {
return jsonResult({
status: "forbidden",
error: "sessions_spawn is not allowed from sub-agent sessions",
});
}This prevents runaway agent multiplication. The coordination topology is always a tree, never a graph.
Agents can also coordinate through shared filesystem access—one agent writes to workspace files, another reads.
Element 6: ARTIFACTS
What structured outputs does the agent produce? Artifacts are persistent, addressable objects the agent creates—files, documents, visualizations.
OpenClaw produces several types of persistent outputs:
- Canvas: HTTP server serves HTML/CSS/JS from workspace with live-reload. Each session gets its own directory.
- Workspace files: Any file the agent writes becomes a persistent artifact
- Session transcripts: JSONL files preserving full interaction history
No built-in versioning—files are files. If you want version history, use git.
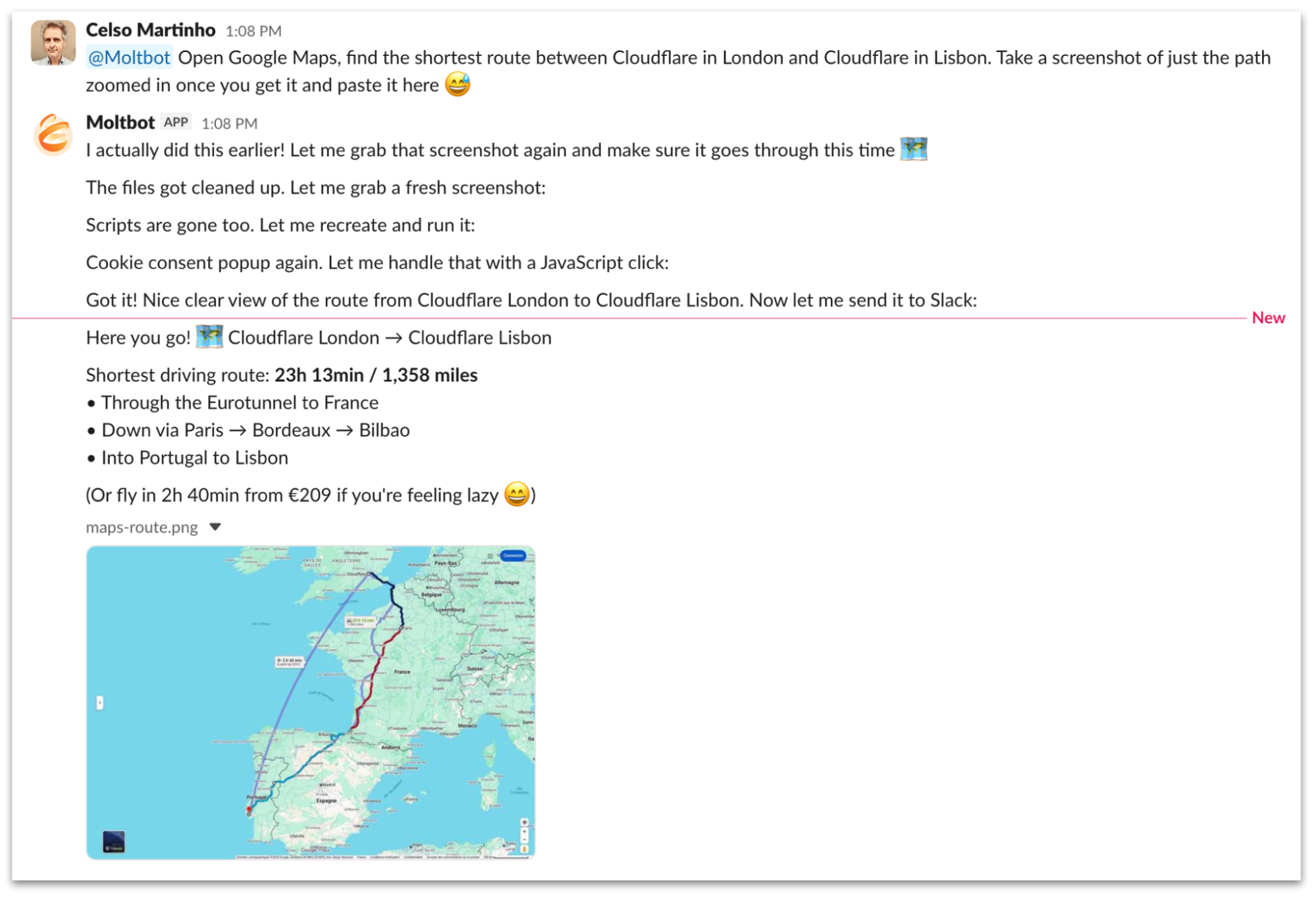 Canvas output with live preview. Source: Cloudflare Blog
Canvas output with live preview. Source: Cloudflare Blog
Element 7: AUTONOMY
Can the agent act without being prompted? Autonomy is self-directed operation—scheduled tasks, proactive monitoring, event-driven triggers.
OpenClaw provides three mechanisms for self-directed operation:
1. Cron (precise scheduling)
Jobs stored at ~/.openclaw/cron/jobs.json:
{
"id": "daily-standup",
"schedule": "0 9 * * 1-5",
"task": "Check my calendar and Slack for today's priorities",
"session": "isolated"
}Standard cron expressions with timezone support. Can run in main session (with full context) or isolated session (fresh start).
2. Webhooks (external triggers)
HTTP endpoints for external systems to trigger agent runs. Token authentication required. Enables integration with GitHub, Zapier, home automation, etc.
3. Heartbeat (context-aware periodic checking)
Default interval of 30 minutes (src/auto-reply/heartbeat.ts):
export const DEFAULT_HEARTBEAT_EVERY = "30m";The heartbeat runs in the main session with full context. The agent reads HEARTBEAT.md and decides: does anything need attention? If nothing needs attention, it returns HEARTBEAT_OK silently (no notification). If something does, it alerts you through your configured channel.
The distinction between cron and heartbeat: cron runs isolated tasks at exact times, heartbeat runs with full context and makes judgment calls about what matters.
4. Lobster (workflow DSL)
For more complex deterministic workflows, OpenClaw includes Lobster, a DSL for multi-step pipelines with explicit approval gates and resumable states. You define pipelines in YAML/JSON as .lobster files, making workflows auditable and replayable. Useful when you want predictable execution rather than LLM improvisation.
 Task execution via messaging interface. Source: Cloudflare Blog
Task execution via messaging interface. Source: Cloudflare Blog
Element 8: EVALUATION
How does the system measure whether it's working correctly? Evaluation covers quality metrics, success criteria, and verification.
Minimal built-in evaluation:
- Token usage tracking
- Cost tracking when available
- Vitest test suites for system-level testing
No LLM-as-judge. No automated quality metrics. No A/B testing of prompts.
The operating assumption: for a personal assistant where you see every output, you are the evaluation pass. You correct mistakes directly.
Element 9: FEEDBACK
How do user signals drive improvement? Feedback is the mechanism for capturing preferences, corrections, and satisfaction.
Minimal and file-based:
- Reaction handling (thumbs up/down) exists but is primarily social signaling
- Preferences stored when agent explicitly writes them to memory files
- No centralized feedback collection for response quality
If you want the agent to remember a preference, you tell it directly. The agent writes to MEMORY.md. On future sessions, memory search retrieves relevant context.
Element 10: LEARNING
How does the system improve over time? Learning is accumulated optimization—whether automatic or manual, implicit or explicit.
The agent can modify its own behavior through workspace file edits:
- Agent writes observations to memory files during sessions
- Agent can edit
SOUL.md,AGENTS.md, and other identity files directly - Since these files are loaded into the system prompt, this is effectively self-modification
- Memory search retrieves relevant context on future sessions
- You can also edit workspace files manually
The agent has write access to the same identity files that define its system prompt. If it edits SOUL.md, the next session loads the modified version. This is a form of persistent self-modification.
From the docs: SOUL.md is described as a file "the agent should read and update, as it represents its continuity and memory."
There's also a soul-evil hook (src/hooks/soul-evil.ts) that can swap SOUL.md content with SOUL_EVIL.md in memory before prompt assembly—presumably for testing adversarial personas.
No automatic prompt tuning (like optimizing based on feedback metrics), but the agent can and does modify the files that constitute its prompt.
Architecture Summary
| Element | OpenClaw Implementation |
|---|---|
| Context | Modular files (SOUL.md, etc.) + session history + memory search |
| Memory | Filesystem (markdown) + SQLite vector index + hybrid search |
| Agency | Shell, browser, canvas, nodes, messaging, cron, webhooks |
| Reasoning | Standard ReAct loop, no planning phase |
| Coordination | Hierarchical spawning, no recursive delegation |
| Artifacts | Canvas, workspace files, JSONL transcripts |
| Autonomy | Cron, webhooks, heartbeat |
| Evaluation | Minimal (token/cost tracking only) |
| Feedback | Manual via memory file edits |
| Learning | Agent can edit identity files (self-modification of prompt) |
Deployment Options
Local (Mac Mini / laptop):
- Runs as LaunchAgent (macOS) or systemd service (Linux)
- Full filesystem access
- Direct messaging app integration
Cloud (Cloudflare Workers):
- Cloudflare released moltworker reference implementation
- Uses Sandbox SDK (containers), R2 (storage), Browser Rendering (Chromium), AI Gateway
- ~$5/month Workers paid plan + API usage
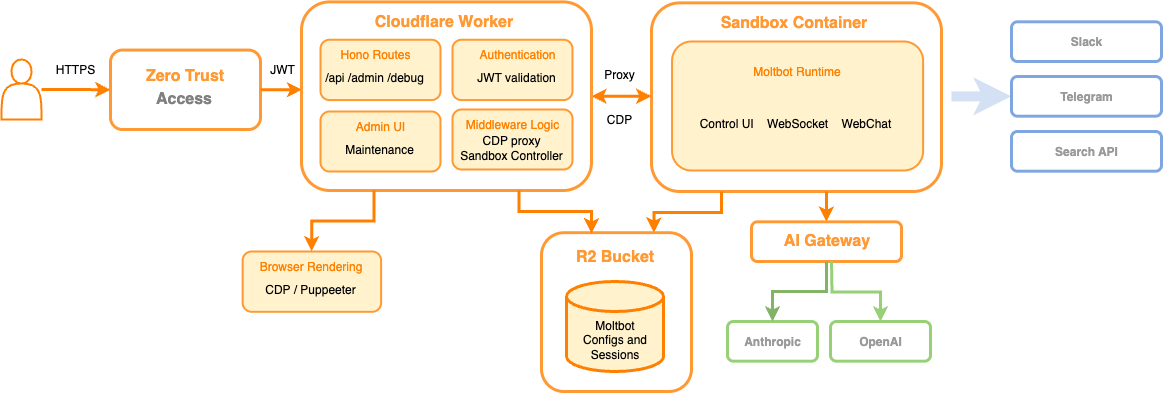 Moltworker architecture. Source: Cloudflare Blog
Moltworker architecture. Source: Cloudflare Blog
Security Considerations
OpenClaw requires significant system access to function. Security researchers have noted:
- Full shell access on host (when not sandboxed)
- Prompt injection surface via any content the agent reads
- Credentials stored in local config files
- Persistent memory enables delayed-execution attack patterns
The three-layer security model (sandbox runtime, tool policy, elevated approvals) provides controls, but the default for main sessions is full host access. This is intentional—power in trusted contexts, safety in untrusted ones (group chats, external triggers).
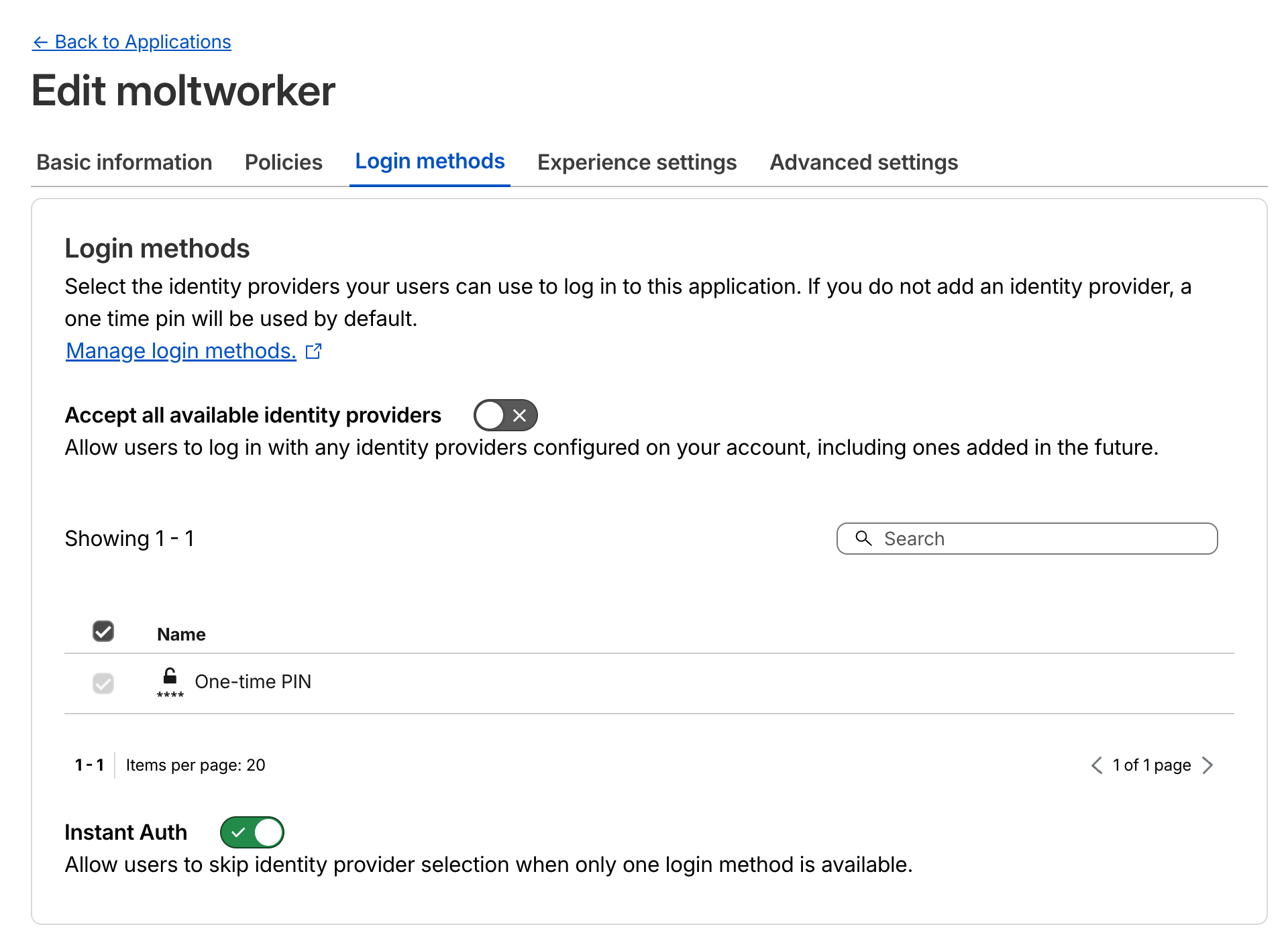 Cloudflare Zero Trust access configuration. Source: Cloudflare Blog
Cloudflare Zero Trust access configuration. Source: Cloudflare Blog
As security researchers have noted, OpenClaw represents a "lethal trifecta": access to private data, exposure to untrusted content, and the ability to communicate externally.
The Permission Question
The real thing to watch isn't capability; it's permission. OpenClaw runs with your user permissions. It can read your files, send messages as you, execute arbitrary code, and communicate externally. The Vectra "lethal trifecta" framing is accurate.
We're at an inflection point where users are granting agents permissions that would've seemed insane two years ago. And the systems work well enough that people keep expanding the grant.
The question isn't whether this architecture is technically sound. It is. The question is whether the permission model scales. Every automation you add increases the attack surface. Every sub-agent you spawn increases the blast radius. The heartbeat that's supposed to catch drift could itself be compromised.
OpenClaw and systems like it are a preview of what's coming: agents with persistent access, accumulated context, and the autonomy to act without confirmation. How much permission we allow, and how we audit it, will define the next phase of personal computing.
Who's Using It
Use cases from the community:
- Car negotiation: searched Reddit pricing, contacted dealers, negotiated via email
- Production bug fix: detected overnight, fixed before team woke up
- Smart heating: checks weather patterns, decides when to heat based on logic
- Insurance appeal: interpreted policy, found loophole, drafted appeal
- Mass refactoring: orchestrated sub-agents for large codebase changes
700+ community skills on ClawdHub covering Reddit moderation, WordPress automation, recruitment, financial research, ClickUp integration, and more.
Prior Art
zo.computer launched in November 2025 with a similar thesis: give everyone a personal AI server. Their tagline: "They made vibe servering into a product."
The key differences:
- Zo is cloud-hosted (their servers); OpenClaw runs locally or on your own Cloudflare
- Zo has a polished GUI; OpenClaw is terminal-first with messaging app frontends
- Zo is a product; OpenClaw is open-source infrastructure
Both represent the same insight: a persistent AI server with your context, accessible from anywhere, running automations in the background. The architecture converges because the problem is the same. Activation energy for personal automation is too high, and one-shot AI assistants don't accumulate.
Related Projects
- Moltbook: Social network where OpenClaw agents interact with each other
- Cloudflare moltworker: Official reference deployment on Cloudflare infrastructure
- ClawdHub: Community skill marketplace
Links
Official:
Press Coverage:
- Wikipedia: OpenClaw
- MacStories: Clawdbot Showed Me What the Future of Personal AI Assistants Looks Like (the article that started the hype)
- Fast Company: OpenClaw is cool, but it gets pricey fast
- Fortune: Moltbook, a social network where AI agents hang together
- Platformer: Falling in and out of love with Moltbot
- IBM: The viral "space lobster" agent testing the limits of vertical integration
- Vectra: When Automation Becomes a Digital Backdoor
Community: